Dots and Dashes
;
Perl is (in)famous for the ability to write programs that look like line noise, and today I will take apart this beautiful piece of code. Written by tybalt89, it can decode sequences of dots and dashes to Latin letters in just 73 characters of code.
Hello Morse
Some time ago I stumbled upon a Google Morse Code experiment. It tells a touching story of a developer Tania Finlayson, born with cerebral palsy and using Morse code to communicate with the world. It also gives you the ability to learn the code for yourself using easy pictographs. There's even a Morse keyboard for Gboard on Android if you want to feel like a telegraph operator!
Since I've always been interested with different forms of alphabets and encoding them, I decided to try it out. A keyboard with just two keys, dot and dash, looked quite unusual at a first glance, but the pictographs turned out to be quite easy to remember. After spending some time with it, I started thinking about decoding these automatically. The similarity to binary code was obvious, so I was sure someone wrote some code for this task already. After some digging I found that beautiful tybalt89's piece of golfed Perl code on the Anarchy golf website, and it was just too good to pass.
Running the code
The program reads morse code text from standard input and prints the decoded data to standard output. To terminate it, press Ctrl-C.
% perl ./morse.pl
.../---/...
sos
...././.-../.-../---/--..-- .--/---/.-./.-../-../.-.-.-
hello, world.
^C
Most of the people when asked about Morse code, know only the universal distress signal SOS. The program has decodes it correctly. I also pasted a friendly greeting, which got out correctly. (If you used an old Nokia phone, you can probably also recall SMS in Morse code .../--/... as an incoming text message alert sound.) But how does it work?
Taking it apart
First try - B::Deparse
We have seen B::Deparse here before -- it's a module producing valid Perl code out of the internal structures after parsing the program. The resulting code is usually not exactly the same as the original source, but there is a good chance it will be more readable - especially when looking at obfuscated one-liners.
% perl -MO=Deparse ./morse.pl
LINE: while (($_ = ARGV)) {
;
;
}
continue {
die unless $_;
}
./morse.pl syntax OK
The while loop didn't come out of nowhere -- it is the consequence of the -p switch. It wraps the code inside a loop reading subsequent lines of input (from stdin or the filenames given as parameters), and its purpose is to make processing streams easy. For example, consider the following program:
% perl -p -e 'tr/a-z/n-za-m/'
caesar cipher
pnrfne pvcure
The -e means just to execute the code given as a parameter; without it, Perl will try to open a file of such name. This is a simple example of a ROT13 cipher and will work the same way -- reading input from stdin and writing to stdout.
Now let's have a look at Deparse output:
% perl -MO=Deparse -p -e 'tr/a-z/n-za-m/'
LINE: while (($_ = ARGV)) {
;
}
continue {
die unless $_;
}
-e syntax OK
As you can see, the -p switch was transformed into the boilerplate code we have seen before.
Search and Replace
Let's continue with the Morse decoder. First, it transforms the input replacing dashes with ones and dots with zeroes:
;
The dash is escaped to make sure it is considered a literal - and not as a range operator (a-z). The escaping is unnecessary here because it is at the first place, but the Deparser put it there anyways.
Let's assume we entered the SOS .../---/... as the input. After this operation, it will be transformed to 000/111/000.
The second line is way more complicated:
;
This is a cleverly written search and replacement function. You probably know its basic form as s/foo/bar/ (replace foo with bar), and here it is used to do the actual conversion.
The "search" part is quite easy -- it is just \d+/?, that is, match one or more digits, with an optional slash at the end. At the end there are two flags, e and g. The g flag means "match globally", or "find all occurences" -- so it will match 000/, 111/ and 000. The search result is saved in the special variable $& (also known as $MATCH if you use English).
The e flag tells Perl to execute the replacement part as Perl code, and use the result for the replacement. This is where the fun begins!
Here's a closer look at the code that gets executed for every match (that is, for every Morse code letter).
substr '01etianmsurwdkgohvf,l.pjbxcyzq', 31 & oct 'b1' . $&, 1;
This looks familiar if you have ever seen the "Morse code tree". Here it is, courtesy of Aris00 from the English Wikipedia:
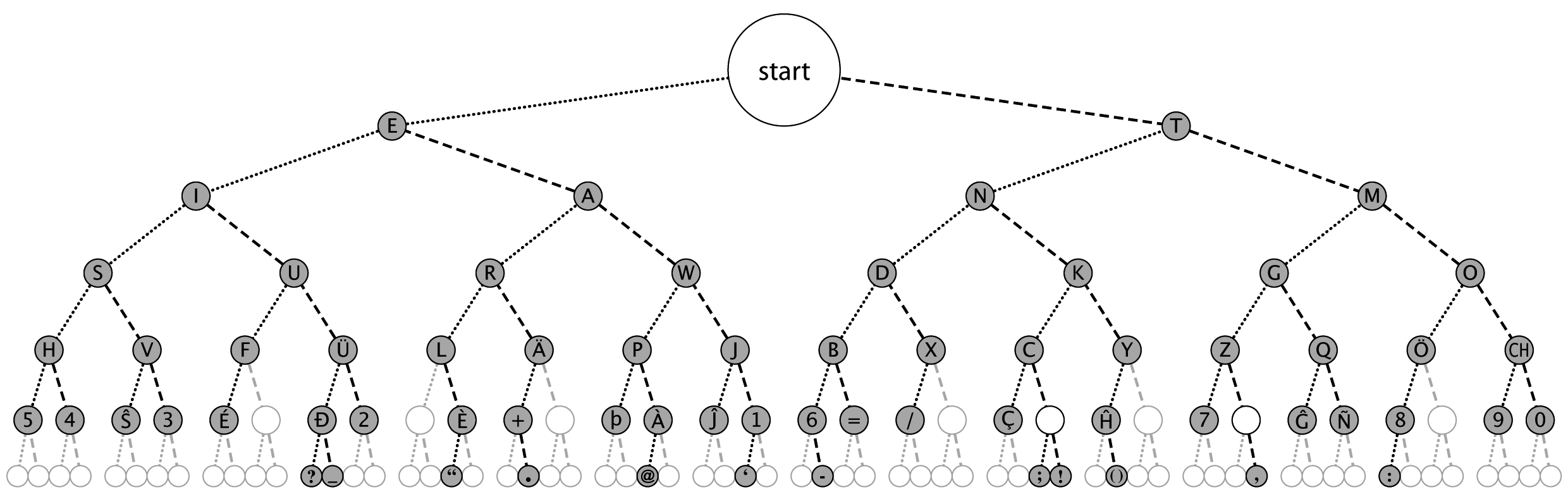
The tree works like this: Take a sequence of dots and dashes, go left for a dot and go right for a dash. Repeat until you run out of symbols, what you got is a decoded letter. Three dots mean you should go left three times from the start, ending at S. Three dashes make you go right three times and voilà, here's an O. (There are easier ways of memorizing the code -- for example, I can't stop thinking of ..- as a Unicorn - it's two eyes and a horn!)
The code works in a similar way. First, the sequence of ones and zeroes, possibly with a trailing slash, needs to be converted from binary into something more useful. Surprisingly, the code uses oct - a function to convert from octal. Turns out oct can also parse binary string, when given a 0b or b prefix, and doesn't mind the slash at the end. The result is then used as an index to find the required character. But why does the code use "b1" there?
It's there to be able to properly recognize leading zeroes in sequences. Let's consider - (T for Tape), .- (A for Archery), ..- (U for Unicorn!) and ...- (V for Vacuum). After converting dots to zeroes and dashes to ones, we will get 1, 01, 001 and 0001, which all have the same numerical value in binary! Adding a one at the beginning fixes the problem, turning these to 11, 101, 1001 and 10001.
Another nice trick the code uses is a logical and of the index value and 31. This is done to ensure the index never goes out of bounds -- it's guaranteed never to be more than 31.
The lookup table
Now let's examine the construction of the string that serves as a lookup table.
01etianmsurwdkgohvf,l.pjbxcyzq
The smallest Morse character can be just a single dot (E) or a single dash (T), so we expect these letters to appear just at the beginning. But because we have added a 1 at the beginning of the binary number in the previous step, we need to deal with it here. E is actually 0b10 (2 dec) and T maps to 0b11 (3 dec), so these letters are at the second and third position of the string. So the 01 at the beginning of the string is just a placeholder, putting the right letters at the right places for decoding.
The rest of the code is simple -- it boils down to a substr call, with a calculated index and a length of one. It is repeated for every morse character matched.
I want a zero
It is possible to make the code display 0 as the output. We just need to find a Morse character decoding to a number that will give 0 after a logical and with 31. Since we can't input a zero directly, let's give it a 32 and see what happens.
32 in binary is 100000. The number is always going to be prefixed with a 1, so what we need is five dots that map to five zeroes. Using this method we can also get a one, entering four dots and a dash (100001 is 33 dec, and gives 1 after a logical and with 31):
% perl ./morse.pl
.....
0
....-
1
^C
This is actually a bug in the code -- five dots stand for 5, and four dots and a dash should decode to 4. Where do I submit a pull request? :)
Can I have an encoder too?
Glad you asked! Let's put what we learned today to good use and write a Morse encoder. It's not going to be as minimalistic as tybalt89's original code, as I'm trying to fight the stereotype that all Perl programs are just unreadable streams of gibberish. But I will reuse the original lookup string. Here we go -- a nice, clean and readable Perl code that encodes letters to dots and dashes.
;
my $lookup = ;
{
my ($l) = @_;
my $enc = , $lookup, $l;
$enc =~ ;
$enc =~ ;
return $enc
}
{
my ($w) = @_;
return , { $_ } //, $w
}
% echo 'code explainer' | perl encoder.pl
-.-./---/-../. ./-..-/.--./.-../.-/../-././.-.
Music to my ears!
Exercise for the reader
How would you extend the programs to support digits too?
Can you make a "golfed" version of the encoder, reducing the number of code characters as much as you can while still providing correct output?